What is Nemotron-3-Nano-30B-A3B?
Nemotron-3-Nano-30B-A3B is NVIDIA’s open-source 31.6B MoE model (3.6B active) optimized for efficient reasoning, agentic tasks, long-context (1M tokens), coding, and chat with hybrid Mamba-Transformer architecture.
When was Nemotron-3-Nano released?
It was released on December 15, 2025, with BF16/FP8 variants; NVFP4 ultra-efficient version followed in late January 2026.
Is Nemotron-3-Nano free to use?
Yes, it’s fully open-source under NVIDIA Open Model License with weights, data, and recipes available on Hugging Face; run locally or via free API tiers.
What are the key benchmarks for Nemotron-3-Nano?
It excels in AIME25 (99.2% with tools), LiveCodeBench (68.3%), GPQA, Arena-Hard-v2, and RULER long-context, often outperforming Qwen3-30B and GPT-OSS-20B.
What hardware is needed for Nemotron-3-Nano?
High-end NVIDIA GPUs (H200/B200 optimal) for real-time/high-throughput; NVFP4 variant boosts efficiency on Blackwell up to 4x.
Does Nemotron-3-Nano support tool calling?
Yes, it features native tool calling, multi-step agentic workflows, and reasoning traces for complex tasks like RAG and automation.
What is the context length of Nemotron-3-Nano?
It supports up to 1 million tokens with strong long-range retention on RULER benchmarks, ideal for massive documents or codebases.
How does Nemotron-3-Nano compare to Qwen3-30B?
It often surpasses Qwen3-30B in reasoning (AIME, LiveCodeBench), agentic performance, long-context, and inference speed while being open-source.
Nemotron 3 Nano

About This AI
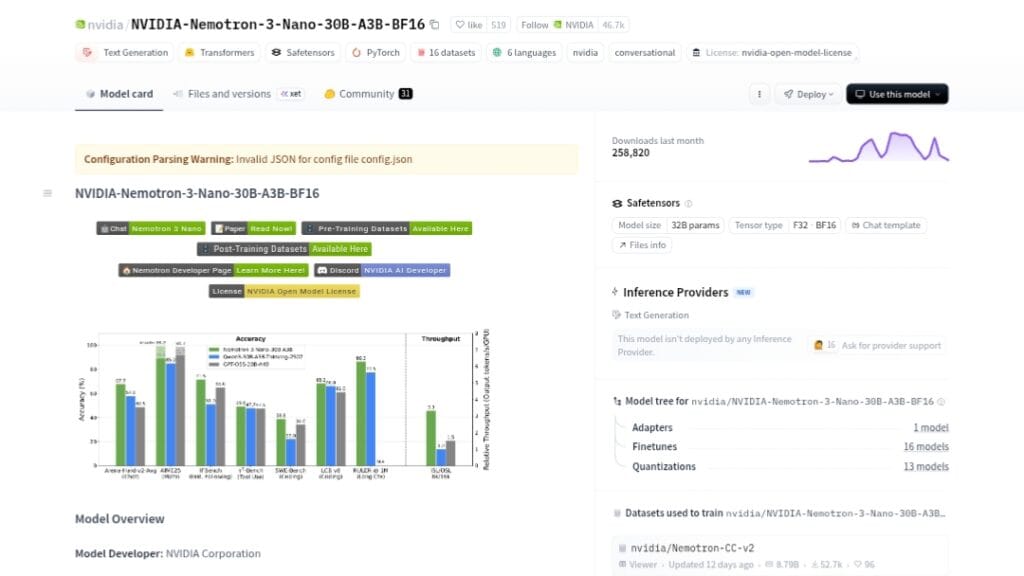
Nemotron-3-Nano-30B-A3B is NVIDIA’s open-source large language model with 31.6B total parameters (3.6B active via sparse MoE) designed for efficient reasoning and chat.
It uses a hybrid Mamba-Transformer MoE architecture with 1M token context length, excelling in agentic tasks, tool calling, multi-step planning, coding, math/science reasoning, and instruction following.
The model generates reasoning traces before final responses (Reasoning ON/OFF toggle), supports English/coding primarily with multilingual capabilities (Spanish, French, German, Japanese, Italian).
Pre-trained on crawled/synthetic data for code, math, science, and general knowledge, then post-trained for reasoning and preferences.
It outperforms peers like Qwen3-30B-A3B and GPT-OSS-20B on benchmarks such as AIME25 (99.2% with tools), LiveCodeBench (68.3%), GPQA, Arena-Hard-v2, and RULER long-context (high retention at 1M tokens).
Inference throughput is significantly higher (e.g., 3.3x vs Qwen3-30B on H200), with variants in BF16, FP8, and NVFP4 for optimized deployment.
Fully open under NVIDIA Open Model License with weights, data, recipes, and NeMo tools for customization.
Available via NVIDIA NIM, Hugging Face, vLLM, and API platforms like OpenRouter (free tier), ideal for developers building specialized agents, chatbots, RAG systems, and enterprise AI applications.
Released December 15, 2025, with NVFP4 update in late January 2026 for even higher efficiency.
Key Features
- Hybrid Mamba-Transformer MoE: Combines state-space efficiency with attention for fast, accurate reasoning
- 1M Token Context Window: Handles extremely long inputs with strong retention via RULER benchmarks
- Reasoning Trace Generation: Produces step-by-step thinking before final answer (toggleable ON/OFF)
- Tool Calling and Agentic Support: Native capabilities for multi-step tasks, RAG, and external tools
- High Throughput Inference: Up to 3.3x faster than Qwen3-30B on H200 hardware
- Multilingual and Coding Strength: Strong in English/coding; supports Spanish, French, German, Japanese, Italian
- Quantization Variants: BF16, FP8, NVFP4 for optimized deployment and up to 4x throughput gains
- Open Weights and Recipes: Full transparency with training data, post-training, and NeMo tools
- Long-Context Fidelity: Maintains coherence at 256K-1M tokens outperforming peers
- Customizable via NeMo: Fine-tuning, distillation, and evaluation frameworks included
Price Plans
- Free ($0): Open-source weights and code under NVIDIA license; run locally or via free tiers on OpenRouter/Hugging Face
- NVIDIA API (Pay-per-use): Token-based pricing via build.nvidia.com (e.g., low input/output rates for NIM deployment)
- Enterprise (Custom): Volume licensing, support, and optimized inference for large-scale use
Pros
- Leading efficiency: Sparse MoE activates only ~3.6B params for high throughput and low cost
- Strong reasoning benchmarks: Tops AIME (99.2% with tools), LiveCodeBench, Arena-Hard-v2 in comparisons
- Massive context support: 1M tokens with excellent long-range recall
- Fully open ecosystem: Weights, data, recipes under NVIDIA license for customization and privacy
- Agentic focus: Optimized for tool use, multi-step planning, and RAG/agent systems
- Fast deployment options: NIM, vLLM, Hugging Face, OpenRouter (free tier available)
- NVFP4 ultra-efficiency: Up to 4x throughput on Blackwell with near-BF16 accuracy
Cons
- Requires high-end hardware: Real-time/high-throughput needs powerful GPUs (H200/B200 optimal)
- Reasoning can be slower: ON mode increases latency for deep thinking tasks
- Limited non-English depth: Primary strength in English/coding; multilingual secondary
- Knowledge cutoff Nov 2025: Post-training data ends November 28, 2025
- Setup complexity: Local running needs dependencies, quantization choices, and config tuning
- No hosted free unlimited: Best performance via paid NVIDIA API or self-hosting
- Early adoption phase: Released Dec 2025; community tools/integrations still maturing
Use Cases
- AI Agent development: Build reliable multi-step agents with tool calling and planning
- Coding and software engineering: Complex debugging, code generation, and repo-scale tasks
- Mathematical and scientific reasoning: Solve advanced math/science problems with high accuracy
- RAG and knowledge systems: Long-context retrieval and synthesis for enterprise search
- Instruction-following chatbots: Create efficient, reasoning-enhanced conversational AI
- Long-document analysis: Process massive texts/codebases without losing context
- Autonomous workflows: Automate multi-tool, high-complexity enterprise processes
Target Audience
- AI developers and researchers: Customizing open models for agents and reasoning
- Enterprise teams: Deploying efficient, private LLMs for production
- Coders and engineers: Needing strong coding/math support with speed
- Agentic AI builders: Focusing on tool use and multi-step intelligence
- Hardware optimizers: Leveraging NVIDIA ecosystem for inference efficiency
- Open-source enthusiasts: Experimenting with hybrid MoE architectures
How To Use
- Access on Hugging Face: Visit huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 for weights
- Run locally with vLLM: Use vllm serve command with model name, dtype auto, and trust-remote-code
- Enable reasoning: Set reasoning ON for trace generation or OFF for direct responses
- Control thinking budget: Adjust effort level (low/high) to balance speed vs depth
- Use via NVIDIA NIM: Deploy on build.nvidia.com for hosted inference or API calls
- Quantize for efficiency: Choose FP8/NVFP4 variants for higher throughput on supported hardware
- Integrate in apps: Use OpenAI-compatible endpoints or NeMo tools for custom agents
How we rated Nemotron 3 Nano
- Performance: 4.8/5
- Accuracy: 4.7/5
- Features: 4.8/5
- Cost-Efficiency: 4.9/5
- Ease of Use: 4.4/5
- Customization: 4.9/5
- Data Privacy: 5.0/5
- Support: 4.6/5
- Integration: 4.7/5
- Overall Score: 4.8/5
Nemotron 3 Nano integration with other tools
- vLLM Inference Engine: High-throughput serving with support for reasoning parser and tool calling
- Hugging Face Hub: Model weights, variants (BF16/FP8/NVFP4), and community inference pipelines
- NVIDIA NIM: Hosted deployment, API access, and optimized inference on NVIDIA hardware
- NeMo Framework: Fine-tuning, evaluation, and customization tools from NVIDIA
- OpenRouter / Other Platforms: Free/public API endpoints for easy testing and integration
Best prompts optimised for Nemotron 3 Nano
- Solve this advanced math problem step-by-step with detailed reasoning: [insert AIME-style problem]
- You are an expert software engineer. Analyze this large codebase snippet and suggest optimizations with reasoning trace: [insert code]
- Using tools if needed, answer this multi-step agentic query: Plan a complex workflow for [task description]
- Provide a thorough, structured reasoning trace for this GPQA-level science question: [insert question]
- Generate a long-form report on [topic] with 1M context support, citing sources and logical chain: [detailed prompt]
FAQs
Newly Added Tools
About Author