What is ShapeR?
ShapeR is a research project from Meta Reality Labs for robust conditional 3D shape generation and metric reconstruction from casual image sequences using multimodal inputs like SLAM points and captions.
When was ShapeR released?
The code, models, and paper were publicly released on January 16, 2026, with arXiv publication 2601.11514.
Is ShapeR free to use?
Yes, the code and pretrained models are freely available on GitHub and Hugging Face under CC-BY-NC license for non-commercial research use.
What license does ShapeR use?
Primarily CC-BY-NC (Creative Commons Attribution-NonCommercial) for research purposes; check NOTICE file for component-specific terms.
What inputs does ShapeR require?
Preprocessed pickle files containing per-object SLAM point clouds, multi-view images, camera poses, text captions, and optionally ground truth meshes.
Does ShapeR support commercial use?
No, the CC-BY-NC license prohibits commercial applications; suitable only for non-commercial research and academic purposes.
Where can I find the ShapeR paper?
The full paper is available on arXiv (2601.11514) and as PDF on the project page: https://facebookresearch.github.io/ShapeR.
Is there a demo or evaluation dataset for ShapeR?
Yes, pretrained models on Hugging Face, a new evaluation dataset with 178 objects, and code for inference/visualization are provided.
ShapeR

About This AI
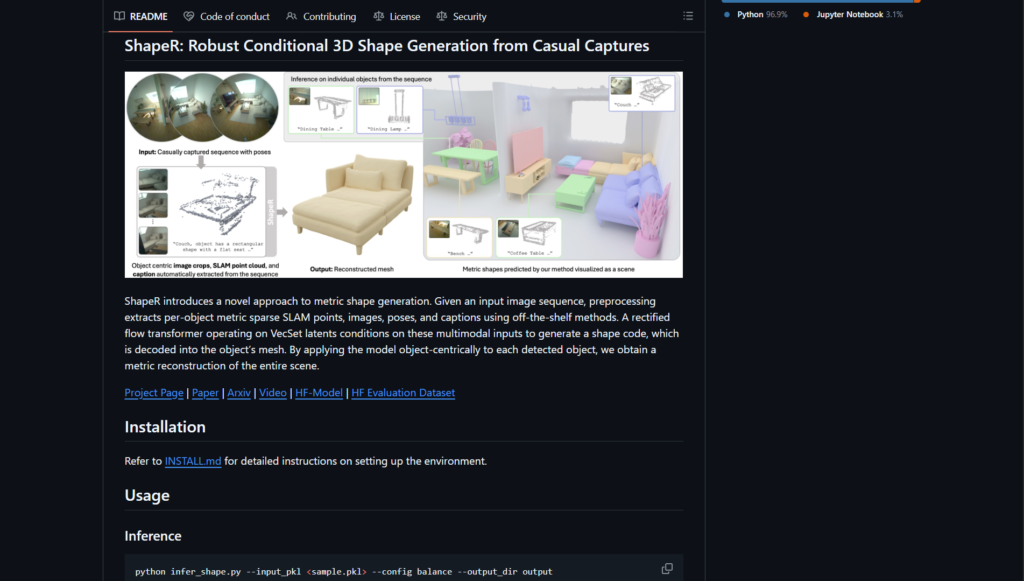
ShapeR is a research project from Meta Reality Labs (Facebook AI Research) that introduces a novel approach to metric 3D shape generation from casual image sequences.
It preprocesses input data to extract per-object multimodal information including sparse SLAM points, images, camera poses, and text captions.
The model generates high-quality, metric-accurate 3D meshes conditioned on these inputs using a rectified flow transformer and VecSet latents.
ShapeR operates object-centrically, enabling scene-wide reconstruction by applying it to each detected object.
It handles real-world challenges like occlusions, clutter, variable viewpoints, and resolutions, outperforming prior methods in in-the-wild scenarios.
The project includes a new evaluation dataset with 178 objects across 7 diverse scenes, featuring paired multi-view images, SLAM points, and complete 3D annotations.
Inference supports configurable modes: quality (16 views, 50 steps), balance (recommended, 16 views, 25 steps), and speed (4 views, 10 steps).
Released on January 16, 2026, with pretrained models on Hugging Face, full code on GitHub, and a research paper on arXiv (2601.11514).
Primarily for non-commercial research use under CC-BY-NC license, it advances conditional 3D reconstruction for applications in AR/VR, robotics, and content creation.
Key Features
- Metric 3D shape generation: Produces scale-accurate meshes from casual captures using SLAM points and images
- Multimodal conditioning: Leverages sparse point clouds, multi-view images, poses, and text captions for robust reconstruction
- Object-centric processing: Reconstructs individual objects then composes into full scenes
- Configurable inference modes: Quality, balance (recommended), and speed options for different trade-offs
- Post-processing tools: Mesh cleanup, simplification, transformation to world coordinates, and visualization
- In-the-wild evaluation dataset: New benchmark with 178 objects in 7 scenes for realistic testing
- Pretrained models: Available on Hugging Face for immediate inference
- Full open-source code: GitHub repo with preprocessing, inference, and data exploration notebooks
Price Plans
- Free ($0): Fully open-source code, pretrained models, dataset, and documentation available on GitHub and Hugging Face under CC-BY-NC license for non-commercial research use
- Commercial (Not Available): License prohibits commercial use; contact Meta for potential licensing inquiries
Pros
- Strong in-the-wild performance: Handles occlusions, clutter, and casual captures better than prior methods
- Metric accuracy: Generates scale-consistent 3D shapes suitable for AR/VR and robotics
- Comprehensive release: Includes code, pretrained models, paper, dataset, and demo resources
- Research-grade quality: Advances conditional 3D generation with rectified flow transformer
- Easy experimentation: Balance mode offers good speed/quality trade-off for testing
Cons
- Non-commercial license: CC-BY-NC restricts use to research; no commercial applications allowed
- Requires preprocessing: Needs SLAM points, poses, and detection (e.g., Aria pipeline) before inference
- Compute-intensive: Quality mode (50 steps) can be slow on standard hardware
- Setup complexity: Involves Conda, CUDA, and specific package installation per INSTALL.md
- Research-focused: Not a user-friendly app; aimed at developers and researchers
- Limited adoption metrics: Very recent release with no widespread user numbers reported
Use Cases
- AR/VR content creation: Generate accurate 3D object models from phone captures
- Robotics simulation: Create metric 3D assets for training and testing in virtual environments
- Research in 3D reconstruction: Benchmarking and extending conditional shape generation methods
- Scene understanding: Reconstruct real-world objects with scale for computer vision studies
- Dataset augmentation: Use generated shapes to expand training data for downstream tasks
Target Audience
- Computer vision researchers: Studying 3D reconstruction and generative models
- AR/VR developers: Needing metric-accurate 3D assets from casual inputs
- Robotics engineers: Requiring realistic object models for simulation
- Academic teams: Using the evaluation dataset and code for papers and experiments
- AI enthusiasts: Experimenting with open-source 3D generation models
How To Use
- Clone repo: Git clone https://github.com/facebookresearch/ShapeR
- Install environment: Follow INSTALL.md to set up Conda, CUDA, and packages
- Download model: Get pretrained weights from Hugging Face (facebook/ShapeR)
- Prepare input: Use preprocessed pickle file with SLAM points, images, poses, captions
- Run inference: python infer_shape.py --input_pkl sample.pkl --config balance --output_dir output
- Customize: Add flags like --do_transform_to_world or --simplify_mesh for post-processing
- Visualize: Check saved meshes and visualizations in output directory
How we rated ShapeR
- Performance: 4.5/5
- Accuracy: 4.7/5
- Features: 4.4/5
- Cost-Efficiency: 5.0/5
- Ease of Use: 3.8/5
- Customization: 4.6/5
- Data Privacy: 5.0/5
- Support: 4.0/5
- Integration: 4.3/5
- Overall Score: 4.5/5
ShapeR integration with other tools
- Hugging Face: Pretrained models and evaluation dataset hosted for easy download and inference
- GitHub: Full source code, installation guide, inference scripts, and data exploration notebooks
- Python Ecosystem: Built with PyTorch and compatible with standard 3D libraries for visualization and processing
- Research Pipelines: Integrates with SLAM systems like Aria MPS for preprocessing input data
- Local Compute: Runs on GPU hardware with no cloud dependency for core reconstruction
Best prompts optimised for ShapeR
- N/A - ShapeR is not a prompt-based generative tool like text-to-image/video; it reconstructs 3D shapes from preprocessed multimodal input data (image sequences, SLAM points, poses, captions) rather than natural language prompts.
- N/A - The model uses fixed conditioning on input data files; no user-provided text prompts are required for shape generation.
- N/A - Focus is on conditional reconstruction from casual captures, not free-form prompting.
FAQs
Newly Added Tools
About Author