What is SpaceTimePilot?
SpaceTimePilot is an open-source video diffusion model (arXiv Dec 2025) that disentangles space and time for controllable generative rendering, allowing independent changes to camera viewpoint and motion sequence from a single input video.
When was SpaceTimePilot released?
The paper was published on December 31, 2025 (arXiv:2512.25075), with code made available around the same time.
Is SpaceTimePilot free to use?
Yes, it’s fully open-source with code on GitHub under standard licensing; no costs for research or personal experimentation.
What does SpaceTimePilot do?
It enables re-rendering dynamic scenes with free control over spatial viewpoints and temporal motion trajectories independently.
How do I access or run SpaceTimePilot?
Clone the GitHub repo at https://github.com/ZheningHuang/spacetimepilot, install dependencies, and follow the provided scripts for inference or training.
Is there a demo or online version of SpaceTimePilot?
No public hosted demo or Hugging Face Space mentioned; it’s a code-based research model requiring local GPU setup.
What datasets does SpaceTimePilot use?
It introduces CamxTime (synthetic full space-time coverage) and uses temporal-warping on existing multi-view datasets for training.
Who created SpaceTimePilot?
Developed by researchers including Zhening Huang, Hyeonho Jeong, Xuelin Chen, Yulia Gryaditskaya, and others from academic institutions.
SpaceTimePilot

About This AI
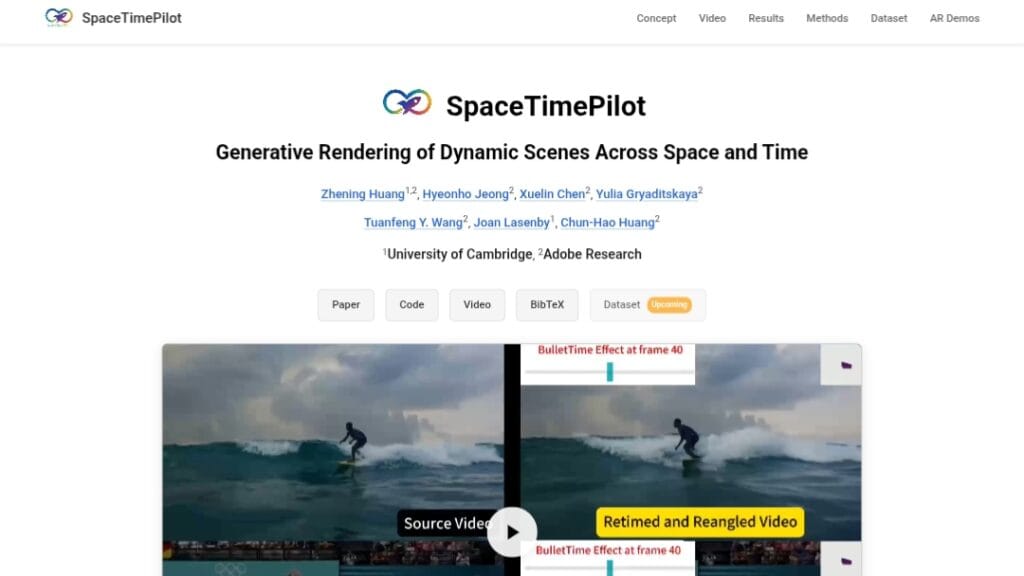
SpaceTimePilot is an open-source research model introduced in a December 2025 arXiv paper, designed for generative rendering of dynamic scenes with disentangled space and time control.
Given a single monocular input video, it enables independent modification of camera viewpoint (spatial changes) and motion sequence (temporal alterations) during the generative diffusion process.
This allows continuous, arbitrary exploration and re-rendering across space and time, such as changing viewpoints freely or altering motion trajectories while maintaining scene consistency.
Core innovations include a time-embedding mechanism for explicit motion control relative to the source video, a temporal-warping training scheme that repurposes multi-view datasets to simulate temporal variations, and an improved camera-conditioning approach starting from the first frame.
It introduces CamxTime, the first synthetic dataset with full space-time coverage for precise dual control training.
The model achieves strong space-time disentanglement, outperforming prior methods on real-world and synthetic evaluations in controllable video generation quality.
Code is available on GitHub for implementation and experimentation, with a project page showcasing results and qualitative comparisons.
As a cutting-edge research tool in video diffusion, it targets computer vision researchers, 3D scene understanding experts, and developers exploring controllable generative video for applications like novel view synthesis, motion editing, and dynamic scene reconstruction.
Key Features
- Space-time disentanglement: Independently controls camera viewpoint and temporal motion sequence in generated videos
- Time-embedding mechanism: Explicit animation time control during diffusion process for precise motion manipulation
- Temporal-warping training: Repurposes multi-view datasets to simulate temporal differences for robust learning
- Improved camera-conditioning: Enables viewpoint changes starting from the first input frame
- CamxTime synthetic dataset: Provides full space-time coverage trajectories for accurate dual-control training
- Controllable re-rendering: Generates new views and motion paths from monocular dynamic video input
- High-quality generative output: Maintains scene consistency, realism, and physics during space-time edits
- Open-source implementation: Full code available on GitHub for training, inference, and experimentation
Price Plans
- Free ($0): Fully open-source research code and model available on GitHub under standard licensing (likely MIT/Apache); no usage fees
Pros
- Pioneering control: First model to fully disentangle and independently control space and time in generative video diffusion
- Strong research results: Demonstrates superior disentanglement and quality over prior controllable rendering methods
- Open-source accessibility: Code freely available for researchers to build upon or replicate experiments
- Innovative training strategies: Temporal-warping and CamxTime dataset enable precise dual control without paired space-time data
- Flexible applications: Enables novel view synthesis, motion editing, and dynamic scene exploration from single videos
- Recent advancement: Builds on latest video diffusion techniques for cutting-edge performance
Cons
- Research-stage tool: Not a ready-to-use consumer app; requires technical setup for running/inference
- Compute-intensive: Video diffusion models demand significant GPU resources for training/inference
- Limited public demos: No hosted Hugging Face Space or easy online demo mentioned; GitHub code only
- No pre-trained weights details: Paper focuses on method; weights availability not explicitly confirmed in sources
- Specialized focus: Primarily for research in controllable video generation, not broad everyday editing
- Evaluation scope: Primarily qualitative and on specific datasets; real-world robustness may vary
Use Cases
- Novel view synthesis: Generate alternative camera angles from monocular dynamic videos
- Motion editing: Alter object trajectories or animation sequences independently of viewpoint
- Dynamic scene exploration: Freely navigate space and time in reconstructed scenes
- Video research prototyping: Test controllable rendering techniques for computer vision papers
- 3D reconstruction enhancement: Improve multi-view consistency in dynamic environments
- Creative video manipulation: Experiment with alternative viewpoints and motions in footage
Target Audience
- Computer vision researchers: Studying video diffusion, controllable generation, and space-time models
- AI developers: Implementing or extending video generation techniques
- Academic teams: Reproducing or building on recent arXiv papers in generative rendering
- Graphics and 3D experts: Exploring novel view synthesis and motion control in dynamic scenes
- Advanced hobbyists: Experimenting with open-source diffusion models locally
How To Use
- Clone repository: Git clone https://github.com/ZheningHuang/spacetimepilot
- Install dependencies: Follow README for required packages (PyTorch, diffusers, etc.) and environment setup
- Prepare input: Provide a monocular dynamic video as source
- Run inference: Use provided scripts for space-time control with specified viewpoint and motion parameters
- Train custom: If needed, use temporal-warping and CamxTime dataset pipelines for fine-tuning
- Visualize results: Generate and compare re-rendered videos with altered space/time trajectories
How we rated SpaceTimePilot
- Performance: 4.6/5
- Accuracy: 4.5/5
- Features: 4.8/5
- Cost-Efficiency: 5.0/5
- Ease of Use: 3.8/5
- Customization: 4.7/5
- Data Privacy: 5.0/5
- Support: 4.0/5
- Integration: 4.2/5
- Overall Score: 4.5/5
SpaceTimePilot integration with other tools
- GitHub Codebase: Open-source repo for local setup, training, and inference integration in custom pipelines
- PyTorch/Diffusers Ecosystem: Compatible with Hugging Face Diffusers library for video diffusion workflows
- Research Frameworks: Easily integrable into academic projects using multi-view or video datasets
- Custom Video Pipelines: Extendable for use in 3D reconstruction, novel view synthesis, or animation tools
Best prompts optimised for SpaceTimePilot
- N/A - SpaceTimePilot is a research video diffusion model controlled via explicit camera/motion parameters, not text prompts like text-to-video tools. Control is achieved through conditioning inputs rather than descriptive prompts.
FAQs
Newly Added Tools
About Author