What is Step 3.5 Flash?
Step 3.5 Flash is StepFun’s open-source sparse MoE foundation model (196B total, 11B active) optimized for fast, frontier reasoning and agentic tasks with 256K context and high throughput.
When was Step 3.5 Flash released?
It was released in early February 2026 (around February 2-3), with weights on Hugging Face and API access shortly after.
Is Step 3.5 Flash free to use?
Yes, the model is completely open-source under Apache 2.0 for local inference; API/hosted access via providers like OpenRouter uses token-based pricing.
What are the key specs of Step 3.5 Flash?
196B parameters (11B active), 256K context, 100-300 tok/s (up to 350 tok/s coding), MTP-3 acceleration, strong on math/coding/agent benchmarks.
How fast is Step 3.5 Flash?
It achieves 100-300 tokens per second in typical use, peaking at 350 tok/s for single-stream coding on high-end hardware.
Can Step 3.5 Flash run locally?
Yes, with GGUF INT4 quantization via llama.cpp or vLLM, it runs on consumer GPUs/Macs with full 256K context support.
What benchmarks does Step 3.5 Flash excel at?
Leads open models in SWE-bench (74.4%), Terminal-Bench (51.0%), AIME/HMMT math, agentic tasks, and overall reasoning averages.
Who should use Step 3.5 Flash?
Developers building agents/coding tools, researchers in reasoning AI, enterprises needing efficient local/cloud LLMs for production workflows.
Step 3.5 Flash

About This AI
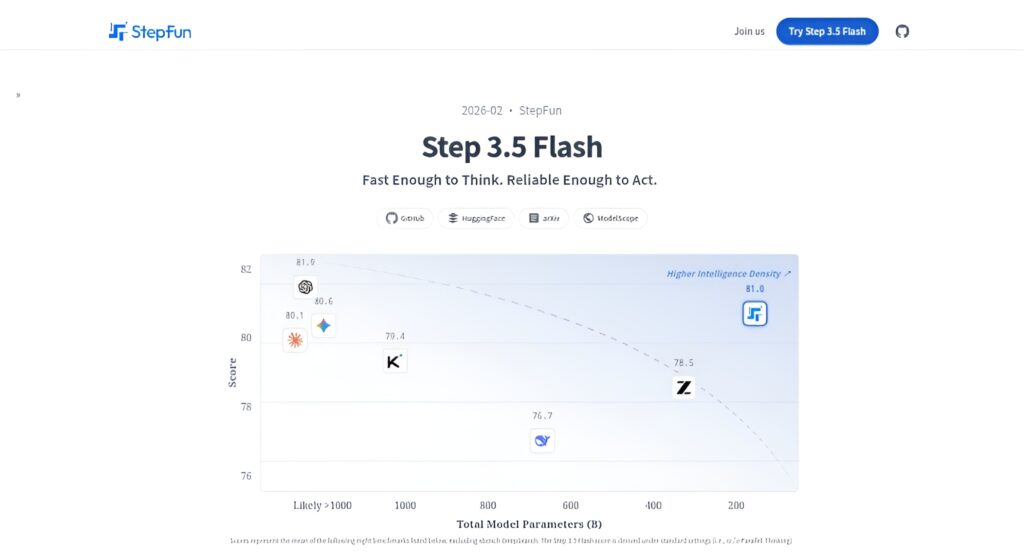
Step 3.5 Flash is StepFun’s most capable open-source foundation model, released in early February 2026 as a sparse Mixture-of-Experts (MoE) LLM optimized for frontier reasoning and agentic capabilities with exceptional efficiency.
It has 196B total parameters but activates only about 11B per token, enabling high intelligence density while maintaining real-time responsiveness and low compute costs.
Powered by 3-way Multi-Token Prediction (MTP-3), it delivers 100-300 tokens per second throughput (peaking at 350 tok/s for coding tasks) and supports a 256K context window via hybrid sliding-window/full attention.
Excels in deep reasoning, math competitions (AIME 2025: 97.3, HMMT 2025: 96.2 avg), coding (SWE-bench Verified: 74.4%, Terminal-Bench 2.0: 51.0%), agentic tasks (τ²-Bench: 88.2), tool-use orchestration, multi-agent frameworks, and professional data analysis.
Features include scalable RL (MIS-PO) for self-improvement, bilingual reliability (English/Chinese), edge-cloud synergy (e.g., Step-GUI), and proactive intent clarification.
Available via API platforms, web chat, mobile apps, local deployment (GGUF INT4 quantized for consumer hardware), and Hugging Face weights under Apache 2.0.
It rivals or exceeds larger closed/open models in many benchmarks while being far more efficient, making it ideal for production agent workflows, coding assistants, research, and real-time applications.
Variants include PaCoRe enhanced version for boosted reasoning scores.
Key Features
- Sparse MoE Architecture: 196B total parameters with only 11B active per token for efficient high-performance inference
- 3-way Multi-Token Prediction (MTP-3): Enables 100-300 tok/s throughput, peaking at 350 tok/s for coding tasks
- 256K Context Window: Long-context support via hybrid sliding-window/full attention with compensation
- Frontier Reasoning: Strong on math (AIME, HMMT, IMO), coding (SWE-bench, Terminal-Bench), and agentic benchmarks
- Agentic Capabilities: Tool-use orchestration, multi-agent frameworks, proactive clarification, and scalable RL (MIS-PO)
- Bilingual Reliability: High performance in English and Chinese for global users
- Local Deployment: GGUF INT4 quantized weights for consumer hardware via llama.cpp
- Edge-Cloud Synergy: Supports hybrid workflows like Step-GUI for real-world applications
- Multi-Agent Research: DeepSearch, ReAct-style agents for complex tasks
- Open-Source Accessibility: Apache 2.0 license with Hugging Face weights, vLLM support, and easy integration
Price Plans
- Free ($0): Open-source model weights and local inference under Apache 2.0; no cost for download/use on your hardware
- API/Hosted (Token-based ~$0.10/M input, $0.40/M output): Pricing via providers like OpenRouter or StepFun platform for cloud access
- Enterprise (Custom): Potential premium support, higher limits, or dedicated deployment through StepFun
Pros
- Exceptional efficiency: High performance with low active parameters and fast inference speeds
- Strong benchmark results: Outperforms or matches larger models in reasoning, coding, and agentic tasks
- Fully open-source: Weights, code, and deployment options freely available under Apache 2.0
- Real-time agent suitability: Low-latency design ideal for production autonomous workflows
- Long-context strength: Reliable 256K handling with reduced compute overhead
- Local runnable: Quantized versions work on consumer GPUs/Macs for private use
- Continuous improvement: RL framework enables self-enhancement and stability
Cons
- Requires strong hardware: Full real-time performance needs high-end GPUs; quantized versions trade some quality
- Longer trajectories: May generate more tokens than some peers for complex reasoning
- Limited free hosted access: Primarily API or local; free tiers (if any) have limits
- Recent release: Community integrations and fine-tunes still emerging
- Potential instability: Edge cases in long-horizon or mixed-language may occur
- No official user count: Adoption metrics not publicly detailed yet
- API pricing varies: Token-based costs on platforms like OpenRouter/StepFun
Use Cases
- Agentic coding and development: Handle complex software engineering tasks, debugging, and repo analysis
- Advanced reasoning and math: Solve competition-level problems, financial modeling, scientific queries
- Autonomous agents: Multi-step tool-use, research orchestration, proactive workflows
- Data analysis and research: DeepSearch, BI engine, stock investment automation
- Simulation and visualization: 3D dashboards, procedural content, scientific viz
- Production chatbots: Fast, reliable responses with long context and tool integration
- Local/private deployments: Run on-prem for sensitive data or edge devices
Target Audience
- Developers and AI engineers: Building agents, coding tools, or local LLMs
- Researchers in reasoning/agentic AI: Experimenting with frontier open models
- Business and finance professionals: Using for analysis, modeling, and automation
- Game/simulation creators: Generating dynamic environments or agents
- Enterprises: Needing efficient, private, high-performance LLMs via API/local
- Open-source enthusiasts: Deploying and fine-tuning frontier models
How To Use
- Download from Hugging Face: Visit huggingface.co/stepfun-ai/Step-3.5-Flash for weights
- Local setup: Use vLLM, llama.cpp, or provided scripts; install dependencies per repo
- Run inference: Load model with INT4/FP8 quantization for efficiency
- Prompt for tasks: Use detailed instructions for reasoning, coding, or agent workflows
- Enable agent mode: Integrate tools (Python exec, search) for multi-step actions
- Cloud API: Use platforms like OpenRouter or StepFun API with model endpoint
- Optimize speed: Leverage MTP-3 and low active params for fast responses
How we rated Step 3.5 Flash
- Performance: 4.8/5
- Accuracy: 4.7/5
- Features: 4.9/5
- Cost-Efficiency: 5.0/5
- Ease of Use: 4.4/5
- Customization: 4.8/5
- Data Privacy: 4.9/5
- Support: 4.5/5
- Integration: 4.7/5
- Overall Score: 4.8/5
Step 3.5 Flash integration with other tools
- Hugging Face: Model weights, inference examples, and community pipelines
- vLLM: High-throughput serving with day-0 support for Step 3.5 Flash
- llama.cpp: Local quantized inference (INT4 GGUF) on consumer hardware
- NVIDIA NIM: Optimized deployment on NVIDIA infrastructure
- Tool-Use Frameworks: Compatible with LangChain, LlamaIndex for agent orchestration
Best prompts optimised for Step 3.5 Flash
- Solve this AIME 2025 problem step-by-step with detailed reasoning: [insert math problem]
- As a senior software engineer, analyze this codebase and suggest refactors to improve performance: [paste code]
- Act as a research agent: DeepSearch and summarize the latest developments in quantum computing from reliable sources
- Build a multi-agent system to plan a stock investment strategy using market data tools: start with current AAPL analysis
- Generate a 3D visualization dashboard for weather patterns using procedural generation and real data inputs
FAQs
Newly Added Tools
About Author