What is NovaSR?
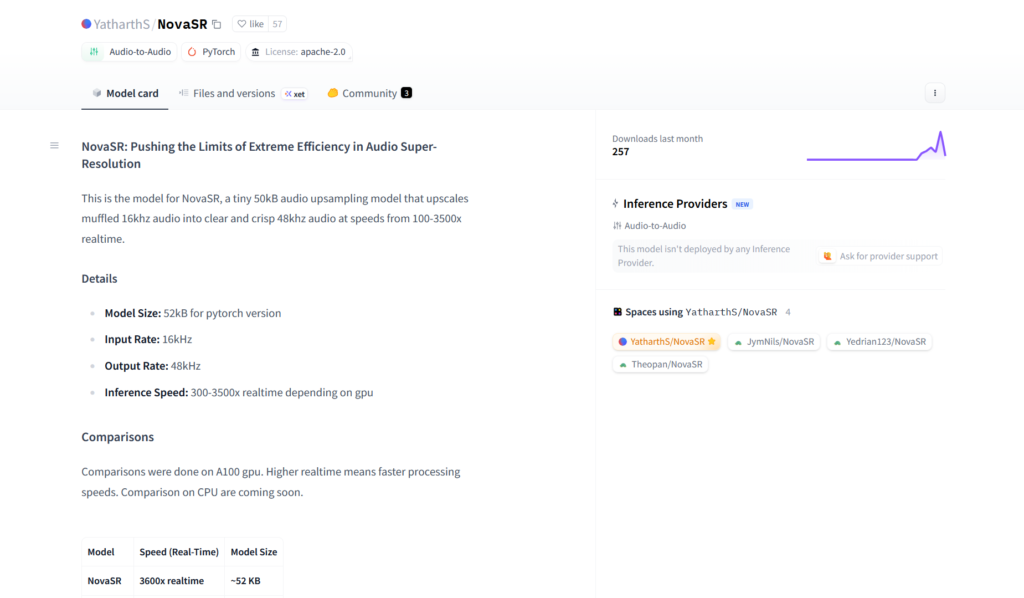
NovaSR is a tiny 52kB open-source audio upsampling model that converts low-quality 16kHz audio to clear 48kHz at extreme speeds (up to 3500x realtime).
Who created NovaSR?
NovaSR was developed by YatharthS (Yatharth Sharma) and released on Hugging Face in late January 2026.
Is NovaSR free to use?
Yes, it’s completely free and open-source under Apache 2.0 license with full weights and code available on Hugging Face.
How fast is NovaSR?
It achieves 300 to 3500x realtime speed depending on hardware, with 3600x demonstrated on A100 GPU (3600 seconds processed in 1 second).
What hardware does NovaSR require?
It runs on almost any device due to its tiny 52kB size; peak speeds need a good GPU, but even CPU works reasonably.
What can NovaSR be used for?
Enhancing TTS outputs, restoring poor-quality audio datasets, real-time audio improvement, mobile/edge applications, and general audio upsampling.
How do I try NovaSR?
Visit the Hugging Face Space at huggingface.co/spaces/YatharthS/NovaSR to upload audio and test instantly, or download from the model page.
What license does NovaSR use?
Apache 2.0, allowing free use, modification, and commercial applications with attribution.
NovaSR

About This AI
NovaSR is a remarkably efficient open-source audio super-resolution model that upscales low-quality 16kHz audio to high-quality 48kHz in real-time with exceptional speed.
With a model size of only 52kB (smaller than a 3-second audio file), it achieves inference speeds of 300 to 3500 times realtime depending on hardware, making it the fastest and smallest audio upsampler available.
It restores clarity to muffled recordings, enhances text-to-speech (TTS) outputs, improves poor-quality datasets, and works on virtually any device due to its tiny footprint.
Developed by YatharthS and released on Hugging Face in late January 2026, NovaSR outperforms much larger models in speed while delivering comparable or better quality in many scenarios.
Benchmarks on A100 GPU show it processing 3600 seconds of audio in just 1 second (3600x realtime), far surpassing competitors like FlowHigh (20x), FlashSR (14x), and AudioSR (0.6x).
The model is fully open-source under Apache 2.0 license, with weights, code, and a demo Space on Hugging Face for instant testing.
It supports PyTorch inference and is ideal for edge devices, mobile apps, real-time TTS enhancement, audio restoration pipelines, and low-resource environments.
No training or fine-tuning required; simply load and run inference on input audio files or streams.
With growing adoption in audio processing communities, NovaSR sets a new benchmark for efficiency in audio AI.
Key Features
- Extreme model efficiency: Only 52kB size, smaller than most audio files, runs on any device
- Ultra-fast inference: 300 to 3500x realtime speed, up to 3600x on A100 GPU
- High-quality upsampling: Converts muffled 16kHz audio to clear 48kHz with detail restoration
- Real-time capable: Suitable for live audio enhancement and streaming applications
- No dependencies overhead: Minimal footprint enables edge and mobile deployment
- PyTorch ready: Easy inference with standard libraries, no special hardware needed for basic use
- Dataset restoration: Improves low-quality audio collections for training or archiving
- TTS enhancement: Boosts clarity and naturalness of synthesized speech outputs
- Open-source accessibility: Apache 2.0 license with full code and weights on Hugging Face
- Demo Space integration: Try directly in browser via Hugging Face Spaces without installation
Price Plans
- Free ($0): Fully open-source model with weights, code, and demo Space; no usage fees or subscriptions required
Pros
- Unmatched efficiency: Smallest and fastest audio upsampler, outperforms larger models in speed
- Universal compatibility: Runs on low-end hardware due to tiny size
- Significant quality boost: Dramatically improves muffled audio for better listening
- Free and open: No costs, full access to code and model under permissive license
- Instant demo access: Hugging Face Space allows quick testing without setup
- Versatile applications: Enhances TTS, restores datasets, real-time audio processing
- Rapid adoption potential: Growing interest in audio AI communities for its performance
Cons
- Very recent release: Limited long-term benchmarks and community feedback
- Hardware-dependent max speed: Peak 3500x requires high-end GPU like A100
- Focused scope: Only upsampling from 16kHz to 48kHz, not full restoration suite
- No built-in denoising: Primarily upsampling; may need pairing with other tools for noise
- Setup for local use: Requires PyTorch and model download for offline inference
- Limited languages/audio types: Optimized for general speech/music, not specialized domains
- Early-stage support: Few integrations or wrappers available yet
Use Cases
- TTS output enhancement: Make synthetic speech sound clearer and more natural
- Audio dataset restoration: Upsample low-res training data for better ML models
- Real-time audio processing: Live upsampling in calls, streaming, or apps
- Mobile/edge deployment: Run on phones or IoT devices with minimal resources
- Podcast/video restoration: Improve old or compressed audio quality
- Game audio improvement: Enhance in-game voice or sound effects
- Research prototyping: Test audio super-resolution efficiency in experiments
Target Audience
- Audio AI developers: Integrating fast upsampling in TTS or speech pipelines
- TTS creators: Improving output quality without heavy models
- Data scientists: Cleaning up low-quality audio datasets
- Mobile app developers: Adding real-time audio enhancement on-device
- Content restorers: Fixing old recordings or compressed media
- Open-source enthusiasts: Experimenting with tiny efficient models
How To Use
- Visit Hugging Face: Go to huggingface.co/YatharthS/NovaSR for model card and download
- Try demo first: Open the Hugging Face Space to upload and test audio instantly
- Install locally: Clone GitHub repo github.com/ysharma3501/NovaSR and install dependencies
- Load model: Use PyTorch to load the .pt file (tiny size)
- Run inference: Pass 16kHz audio tensor; get 48kHz upscaled output
- Integrate: Add to TTS pipeline or audio processing script for real-time use
- Optimize speed: Use GPU acceleration for maximum 3500x realtime performance
How we rated NovaSR
- Performance: 4.9/5
- Accuracy: 4.7/5
- Features: 4.5/5
- Cost-Efficiency: 5.0/5
- Ease of Use: 4.6/5
- Customization: 4.4/5
- Data Privacy: 5.0/5
- Support: 4.3/5
- Integration: 4.5/5
- Overall Score: 4.7/5
NovaSR integration with other tools
- Hugging Face Spaces: Browser-based demo for instant audio upload and upsampling without installation
- GitHub Repository: Full source code for local setup, modification, or integration into projects
- PyTorch Ecosystem: Native compatibility with PyTorch for easy inclusion in ML pipelines
- TTS Frameworks: Plug into Coqui TTS, Piper, or Tortoise TTS to enhance output audio quality
- Audio Processing Tools: Chain with libraries like librosa, torchaudio, or FFmpeg for preprocessing/postprocessing
Best prompts optimised for NovaSR
- Not applicable - NovaSR is an audio upsampling model that processes raw 16kHz audio files directly without text prompts; it works on input waveforms rather than descriptive text.
- N/A - This tool requires audio input (e.g., upload WAV/MP3 at 16kHz) instead of text prompts for generation.
- N/A - Focus is on signal processing (upsampling) rather than prompt-based generation; no text input needed.
FAQs
Newly Added Tools
About Author